
Across industries, organisations are pouring investment into AI, yet a striking number of pilots stall before they ever reach production. The culprit is rarely the model. It is the data underneath it.

At enreap, we have seen this pattern repeatedly: ambitious AI initiatives that hit a ceiling not because the technology is not capable, but because the data feeding it is fragmented, inaccessible, or simply not ready. Building AI-ready data is the foundational step that most organisations skip and the one that determines whether AI delivers real business value or just a polished demo.
Data silos are quietly killing your AI ambitions
Enterprise data does not live in one tidy place. It is scattered across data lakes, on-premises transaction systems, cloud storage, document repositories, and countless SaaS tools, often locked away in formats that AI systems struggle to interpret. Without a unified view spanning all of this, your AI is working with a fraction of what it needs.
What makes this worse is the nature of the data itself. Up to 90% of what enterprises generate is unstructured: invoices, contracts, customer conversations, emails, and reports. This data carries an enormous signal, but extracting it requires more than a basic retrieval layer.
“Conventional retrieval approaches were built for a simpler era. In today’s agentic AI landscape, they leave most of your enterprise knowledge on the table.”
- Fragmented data landscape
Without a centralised view, data duplicates across repositories, governance breaks down, and AI outputs suffer from incomplete context.
- Locked by default
Access limitations that protect data can also prevent AI from doing its job effectively. Over-restriction is as costly as under-protection.
- Unstructured complexity
Videos, contracts, and customer feedback contain critical insights that standard retrieval methods cannot reliably extract or connect.
- Limits of conventional RAG
Vector-based retrieval excels at semantic search but struggles with mixed data types, access control, and the complex semantics agentic AI demands.
Making data AI-ready without starting from scratch
The good news: you do not need to rip and replace your current infrastructure. Data migration is a choice, not a requirement. What matters is creating unified, governed access to your data estate, wherever that data lives today.
enreap helps organisations build this foundation through a set of interconnected capabilities: intelligent data integration, hybrid retrieval across structured and unstructured sources, governance that travels with the data, and a flexible architecture that preserves existing investments while opening them up to AI-driven workloads.
- Data management by design
Build a clear strategy so every incremental decision moves you in the right direction.
- Protect existing investments
Extend and integrate what you have. Do not replace it with yet another new platform.
- Access in place
Connect your data across its current locations instead of moving it all to a central store.
- Open by default
Open formats and standards prevent lock-in and keep your data ecosystem free to evolve.
- Governance as infrastructure
Access controls and data quality policies must be baked in, not bolted on after the fact.
- Human in the loop
Responsible AI deployment means keeping people positioned to review, refine, and course-correct.
From assessment to production: enreap’s readiness journey
Getting data AI-ready is not a single project. It is a progression. enreap works alongside your team across four stages, moving at the pace that is right for your organisation and building on what you already have at each step.
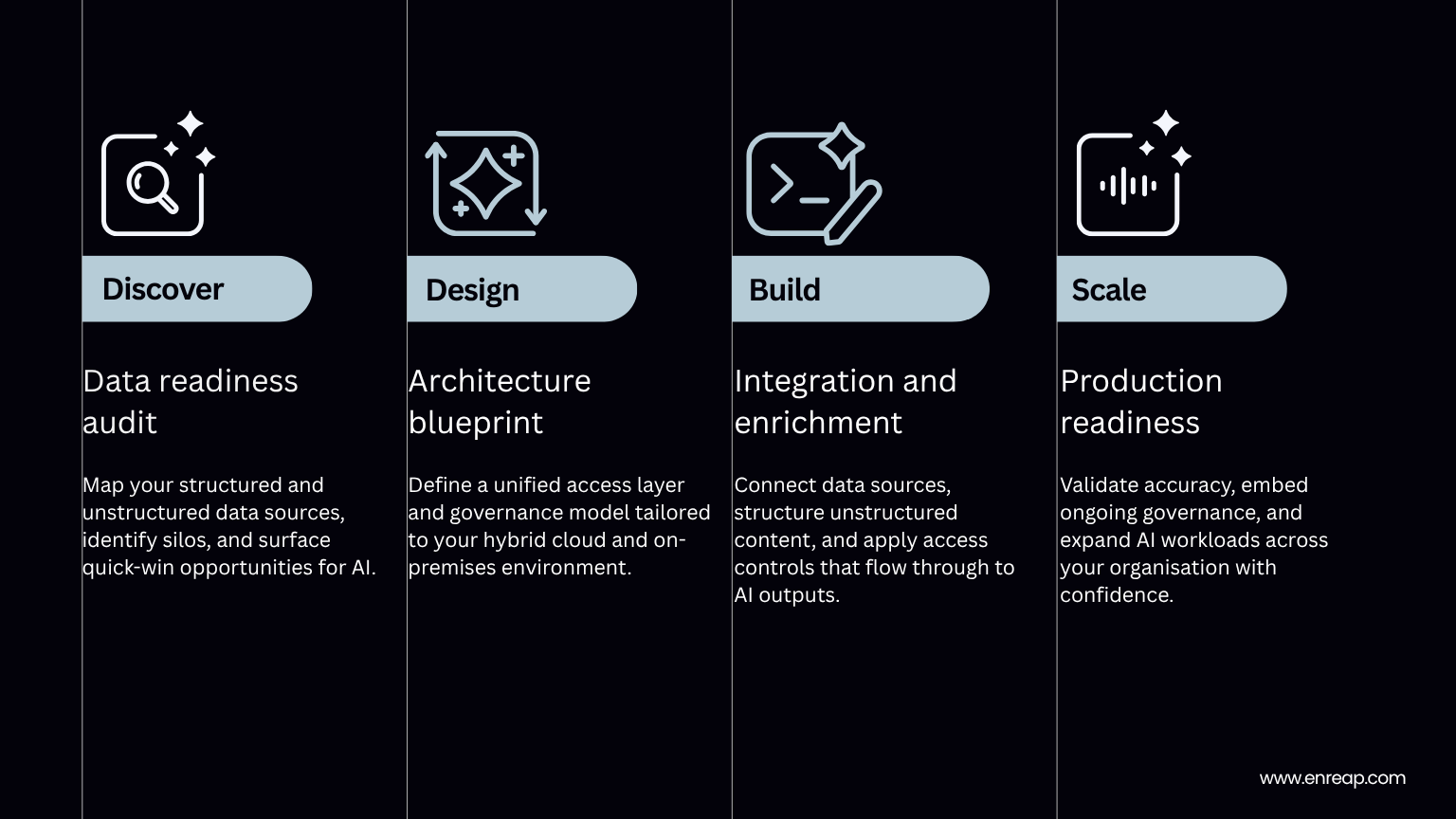
The result is a data foundation your AI can rely on, one that improves with use, adapts to new workloads, and does not require starting over every time your infrastructure evolves.
Ready to assess your organisation’s AI and Data readiness?
Talk to enreap’s team to understand where your data estate stands today and what it would take to unlock its full potential for AI.